FPGA can be used to handle multiple computing-intensive tasks. Relying on the pipelined parallel architecture, FPGA has technical advantages over GPU and CPU in the return delay of computing results.
Computing-intensive tasks: Matrix operations, machine vision, image processing, search engine sorting, asymmetric encryption and other types of operations are computing-intensive tasks. This kind of operation task can be unloaded to FPGA by CPU.

FPGA performance in performing compute-intensive tasks:
The computing performance is relative to CPU: for example, Stratix series FPGA performs integer multiplication, its performance is equivalent to that of 20-core CPU, and its performance of floating-point multiplication is equivalent to that of 8-core CPU.
The computing performance is compared with GPU:FPGA for integer multiplication and floating-point multiplication, and there is an order of magnitude difference between the performance and GPU. It can be close to GPU computing performance by configuring multipliers and floating-point computing units.
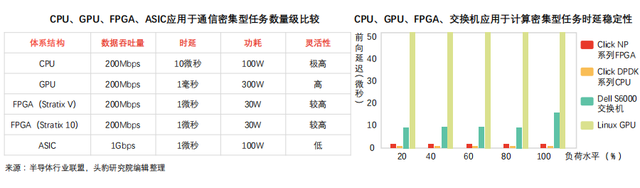
The core advantage of FPGA in implementing computing-intensive tasks: search engine sorting, image processing and other tasks require strict time limits for the return of results, and it is necessary to reduce the computing step delay. Under the traditional GPU acceleration scheme, the packet size is large and the delay can reach the level of milliseconds. Under the FPGA acceleration scheme, the PCIe delay can be reduced to microseconds. Driven by forward technology, the data transmission delay of CPU and FPGA can be reduced to less than 100 nanoseconds.
FPGA can build an equal number of pipelines (pipeline parallel structure) according to the number of packet steps, and the packets can be output immediately after being processed by multiple pipelines. The GPU data parallel mode relies on different data units to process different data packets, and the data units need consistent input and output. For streaming computing tasks, FPGA pipelined parallel architecture has a natural advantage in terms of latency.
When FPGA is used to deal with communication-intensive tasks, it is not limited by the network card, and is better than CPU in terms of packet throughput and delay, and has strong delay stability.
Communication-intensive tasks: symmetric encryption, firewall, network virtualization and other operations belong to communication-intensive computing tasks. Compared with computing-intensive data processing, communication-intensive data processing has lower complexity and is easily limited by communication hardware devices.


FPGA performs communication-intensive tasks:
oneThroughput advantage: when dealing with communication-intensive tasks, CPU scheme needs to receive data through the network card, which is easily limited by the network card performance (the wire speed processing 64-byte packet network card is limited, the number of slots of CPU and motherboard PCIe network card is limited). GPU scheme (high computing performance) to deal with communication-intensive task packets lack of network port, need to rely on the network card to collect data packets, the data throughput is limited by CPU and network card, and the delay is long. FPGA can access 40Gbps and 100Gbps network lines, and process all kinds of data packets at wire speed, which can reduce the configuration cost of network card and switch.
twoDelay advantage: the CPU scheme collects data packets through the network card and sends the calculation results to the network card. Limited by the performance of the network card, under the framework of DPDK packet processing, the delay of CPU in dealing with communication-intensive tasks is nearly 5 microseconds, and the stability of CPU delay is weak. Under high load, the delay may exceed tens of microseconds, resulting in task scheduling uncertainty. FPGA does not need instructions and can ensure stability and very low latency. FPGA in cooperation with CPU heterogeneous mode can expand the application of FPGA scheme in complex devices.
FPGA deployment includes clustering, distributed and so on, and gradually transitions from centralization to distribution. under different deployment modes, the server communication efficiency and fault conduction effect are different.
FPGA embedded power burden: FPGA embedding has little impact on the overall power consumption of the server. Take the FPGA accelerated machine translation project carried out by Catapult and Microsoft as an example, the total computing power of the acceleration module reaches 103Tops/W, which is equivalent to that of 100000 GPU. Relatively speaking, embedding a single FPGA increases the overall power consumption of the server by about 30W.
Features and limitations of FPGA deployment:
oneCharacteristics and limitations of cluster deployment: FPGA chips form a dedicated cluster and form a supercalculator composed of FPGA accelerator cards (for example, the early experimental boards of Virtex series deploy 6 FPGA on the same silicon chip, and 4 experimental boards are carried on a unit server).
Dedicated cluster mode cannot communicate between different machine FPGA
Other machines in the data center need to send tasks to the FPGA cluster centrally, which can easily cause network delay.
A single point of failure limits the overall acceleration capacity of the data center

